
¡Me encanta el olor a software libre por las mañanas! Y más cuando una aplicación privativa que me gusta se vuelve un dolor de muelas por sus restricciones. Entonces es el momento de buscar alternativas de software libre. mis requerimientos open source alternativa a slack multiplataforma: linux, windows, android… sin […]
diego
122 entradas
Se nos llena la boca (a mí el primero) diciendo que tenemos que cifrar los dispositivos de almacenamiento, sobre todo los portátiles y los discos duros externos, para luego tener una única contraseña durante toda la vida útil del dispositivo. En mi trabajo no tengo instalado linux en la estación […]

O dicho en el idioma de los errores de sistema, ERROR 2006 (HY000) at line 21232: MySQL server has gone away. $ mysql -h localhost -u user -pUltraSecurePass mydatabase < dump.sql ERROR 2006 (HY000) at line 21232: MySQL server has gone away $ El lío El error me apareció cuando […]
Inciso: Dabo, te lo dije, te advertí que no pararía hasta terminar sabiendo cómo hacer funcionar esto 🙂 Tengo varias web, varios WordPress y un puñado de dominios. Es, creo yo, lo habitual cuando te mueves por estas aguas y a cada proyecto, idea o viaje místico le asocias un […]
Tener tu propia nube, ya sea en un servidor casero (de las raspi en adelante) o en algún servidor alquilado, es sencillísimo desde la llegada de Owncloud. De hecho, mi nube cuenta ya con un par de años y más de 20 GB de ficheros a cuestas. Pero desde que […]
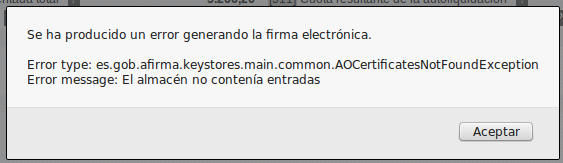
Desde el año pasado (creo) la AEAT (hacienda, para el que no sea de siglas), tiene un programa Java que sustituye al programa PADRE. Al final creo que se cansaron de mantener varios sistemas para cumplir telemáticamente con el fisco y lo hicieron en Java. Yo me lo imagino tal […]
Resulta que tres elementos que conocemos, admiramos y queremos (y en ocasiones padecemos, ¿eh, presionator? :)) se han juntado para darle forma a un blog llamado Aprendiz de Sysadmin que ha abierto sus puertas hace un mes. @fpalenzuela, @itzala74 e @israelmgo van a escribir sobre administración de sistemas en varios […]
Cuando se pega mucho (pero mucho, mucho) con debian, lleva un momento en que empieza a hacer o modificar paquetes y es entonces cuando el uso de un repositorio personal es una buena idea. Hace unos años, crear y sobre todo mantener un repositorio de paquetes de debian era doloroso […]

Después de casi diez años usando la versión debianizada del mejor navegador que ha surcado internet, Mozilla Firefox, acabo de ver en los paquetes de debian que ya está de vuelta en los repositorios, al menos en la rama testing (si, lo sé pero es uno de esos vicios confesables...). […]